Tesseract
- ARGOSLABS
| Tesseract |
|---|---|
Author: Jerry Chae It is one of most used Open Source OCR solutions https://en.wikipedia.org/wiki/Tesseract_(software) Tesseract is an optical character recognition engine for various operating systems. It is free software, released under the Apache License. Originally developed by Hewlett-Packard as proprietary software in the 1980s, it was released as open source in 2005 and development has been sponsored by Google since 2006. |
Prerequisite
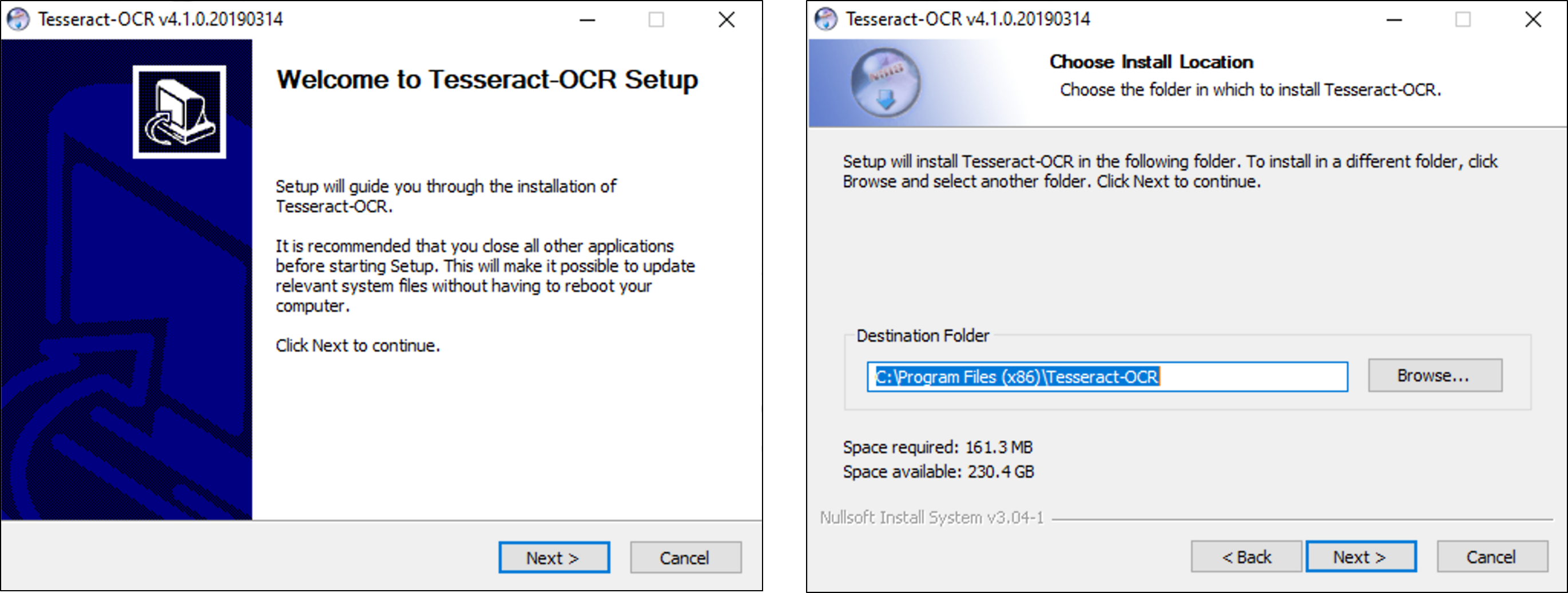
You must have the local Tesseract module installed.
Installation file name is: tesseract-ocr-w32-setup-v4.1.0.20190314.exe
If the local Tesseract module has not been installed, the plugin will fail to run and will give a message to ask installation as well as the URL to download the module.
The message contains the module file name and the URL to download it from.
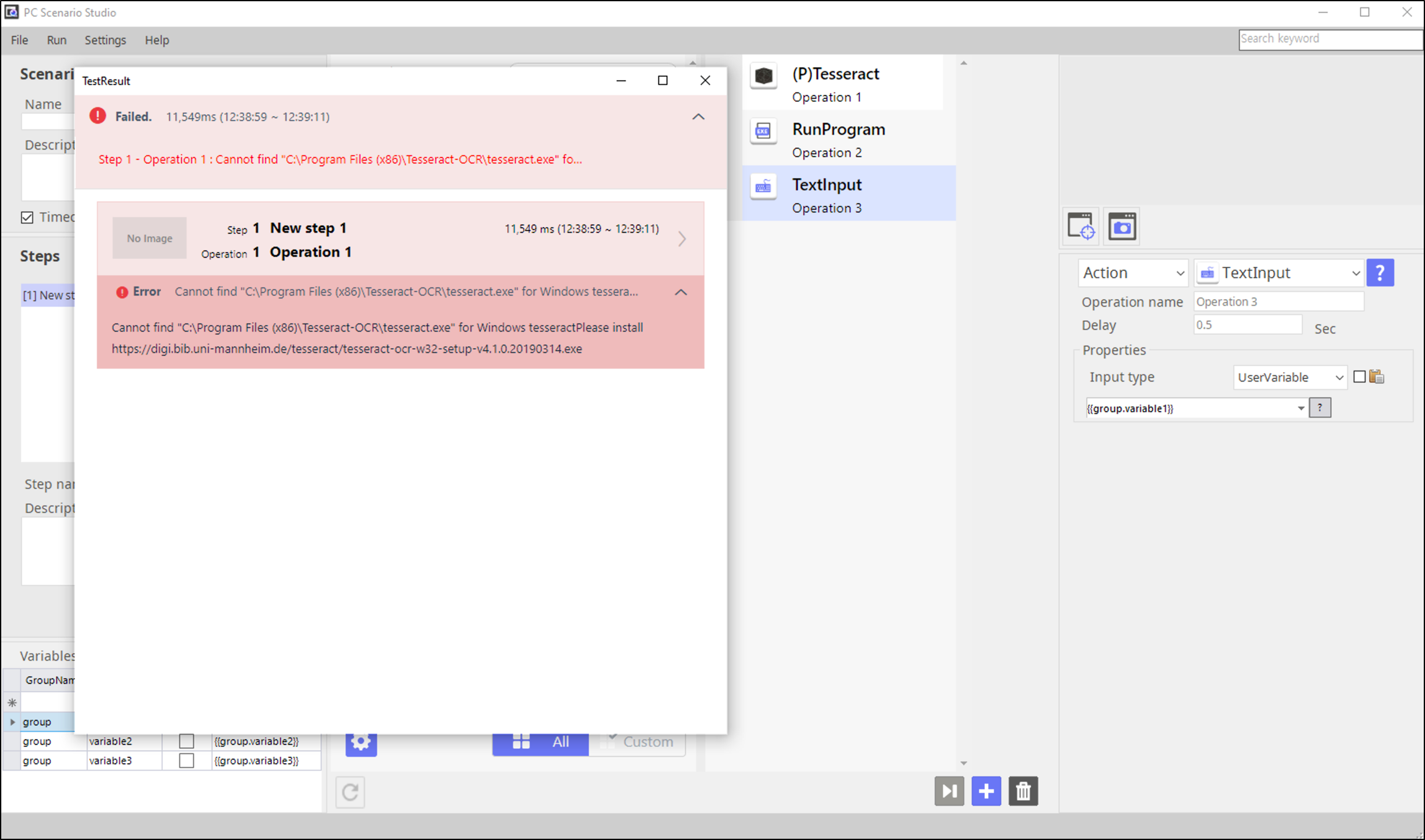
Here is the download URL.
https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w32-setup-v4.1.0.20190314.exe
Contents
Operations and how to set parameters
Operations and how to set parameters
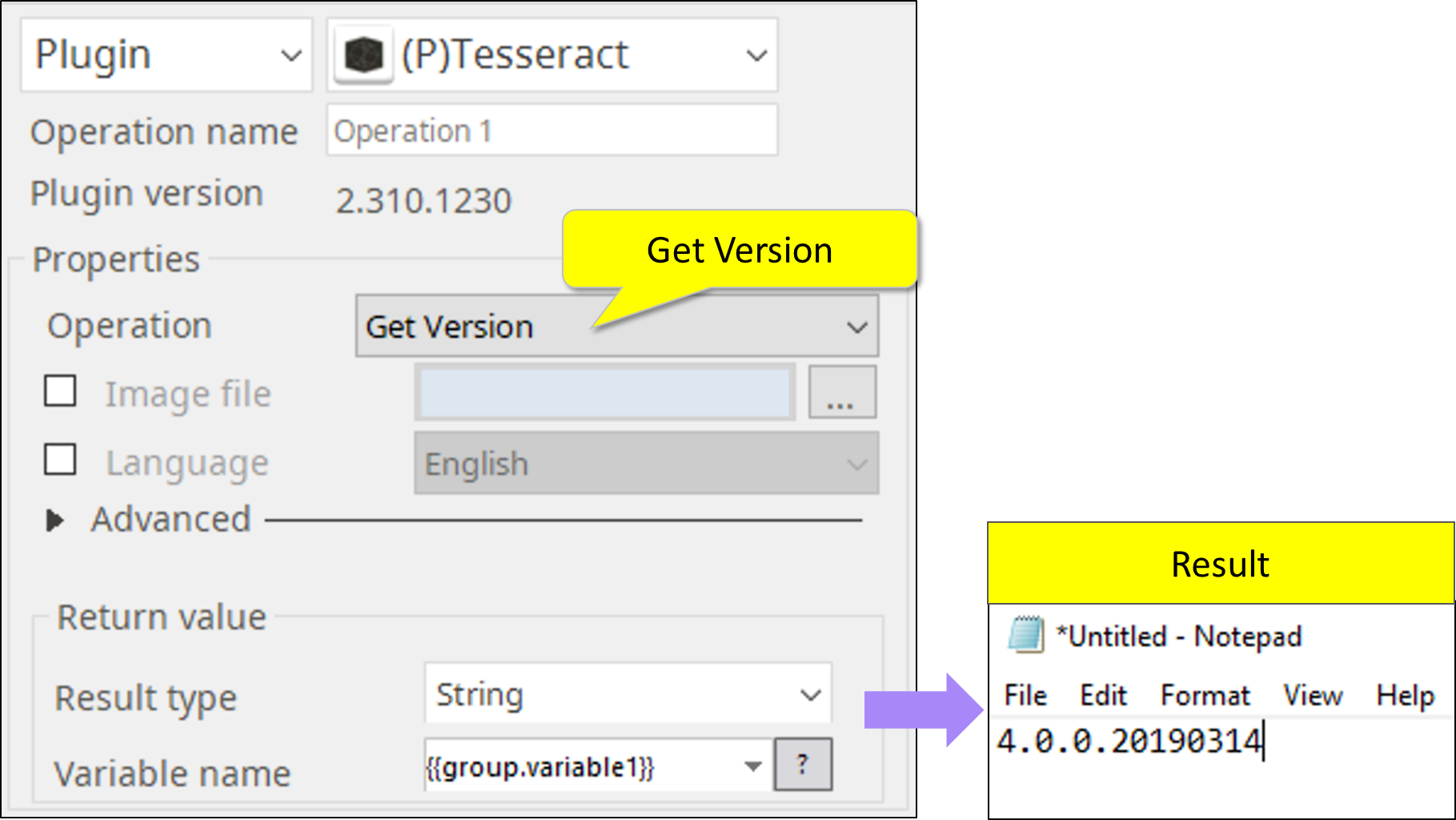
1. Get Version
This operation simply returns the version number of locally installed module.
2. List of Languages
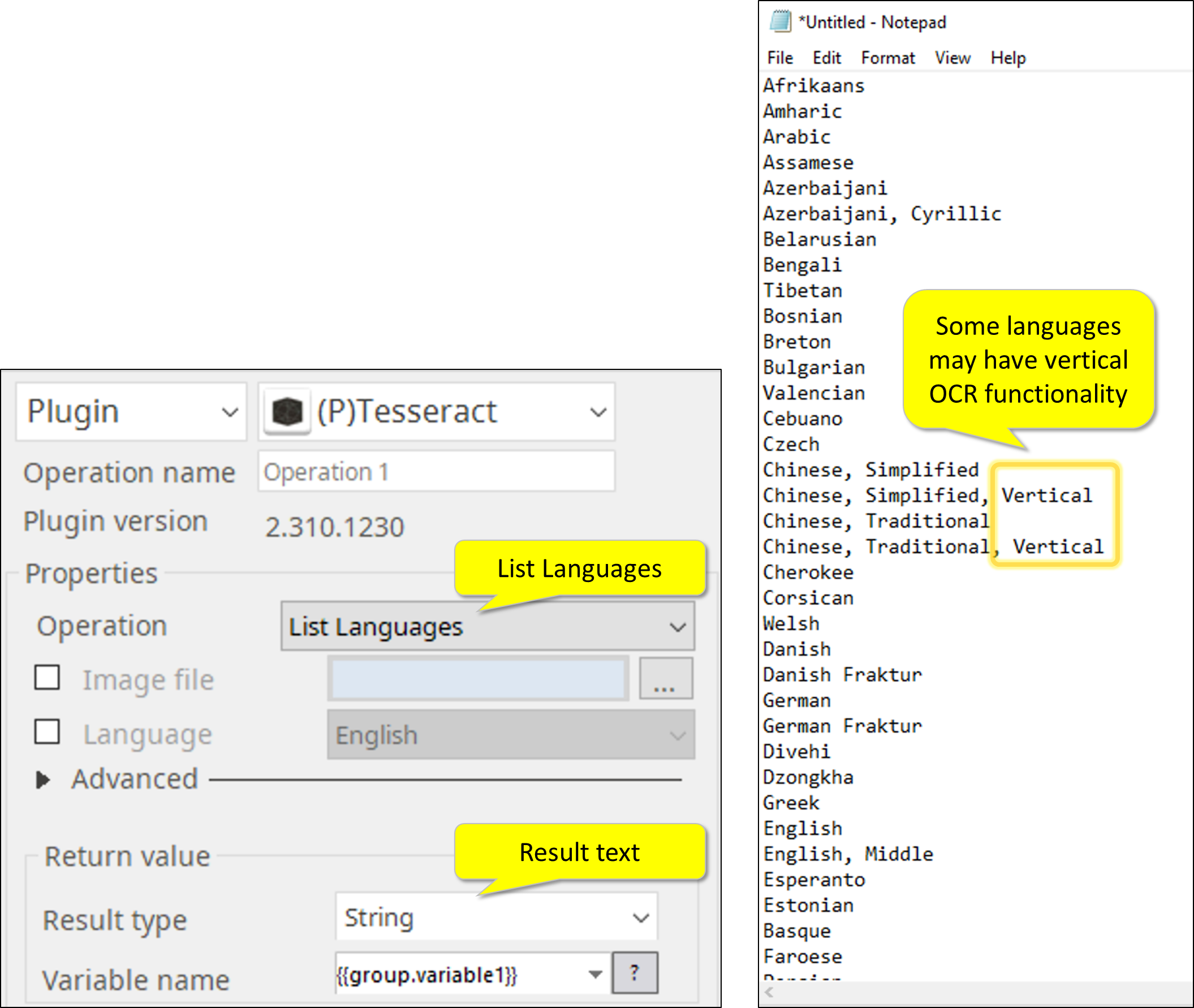
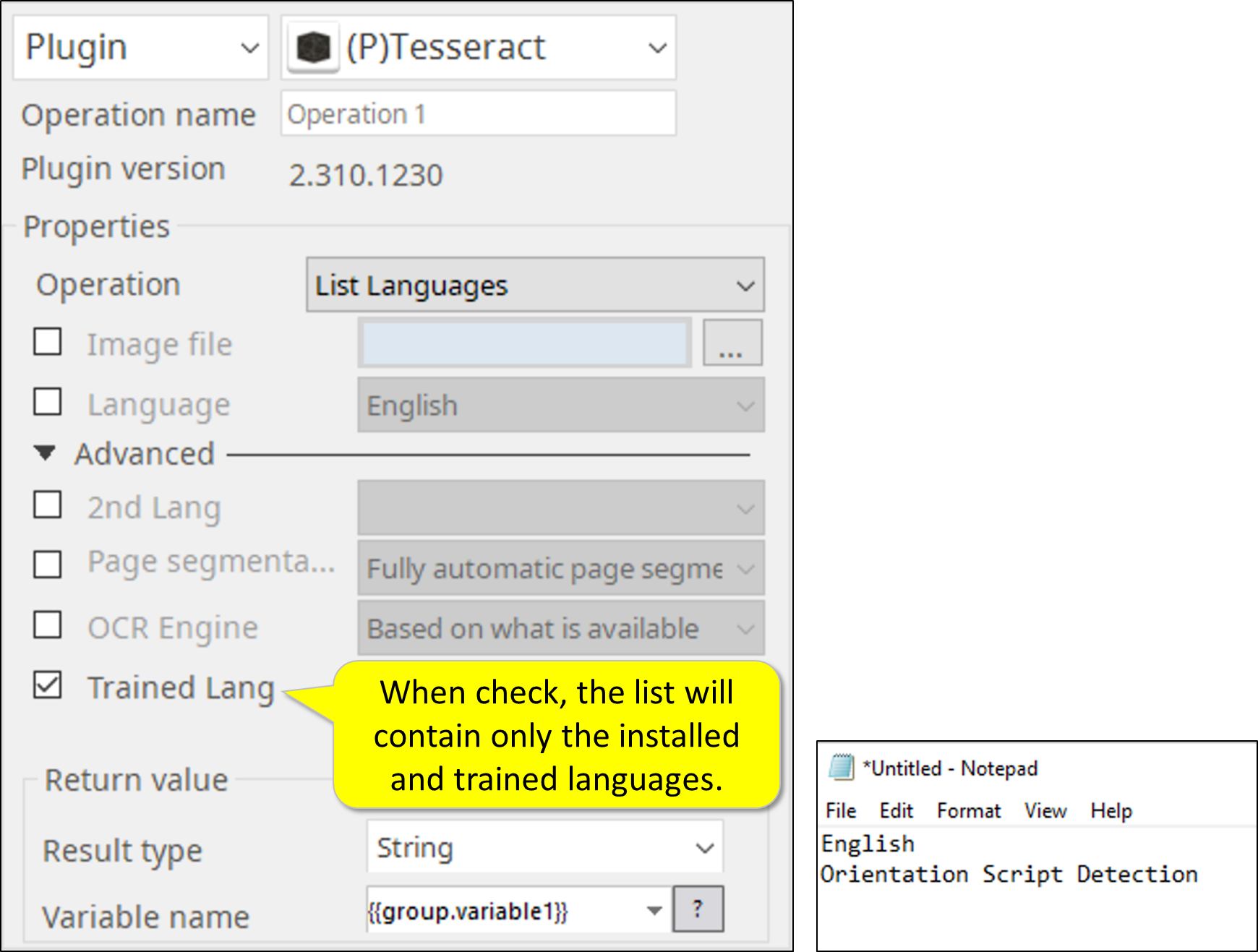
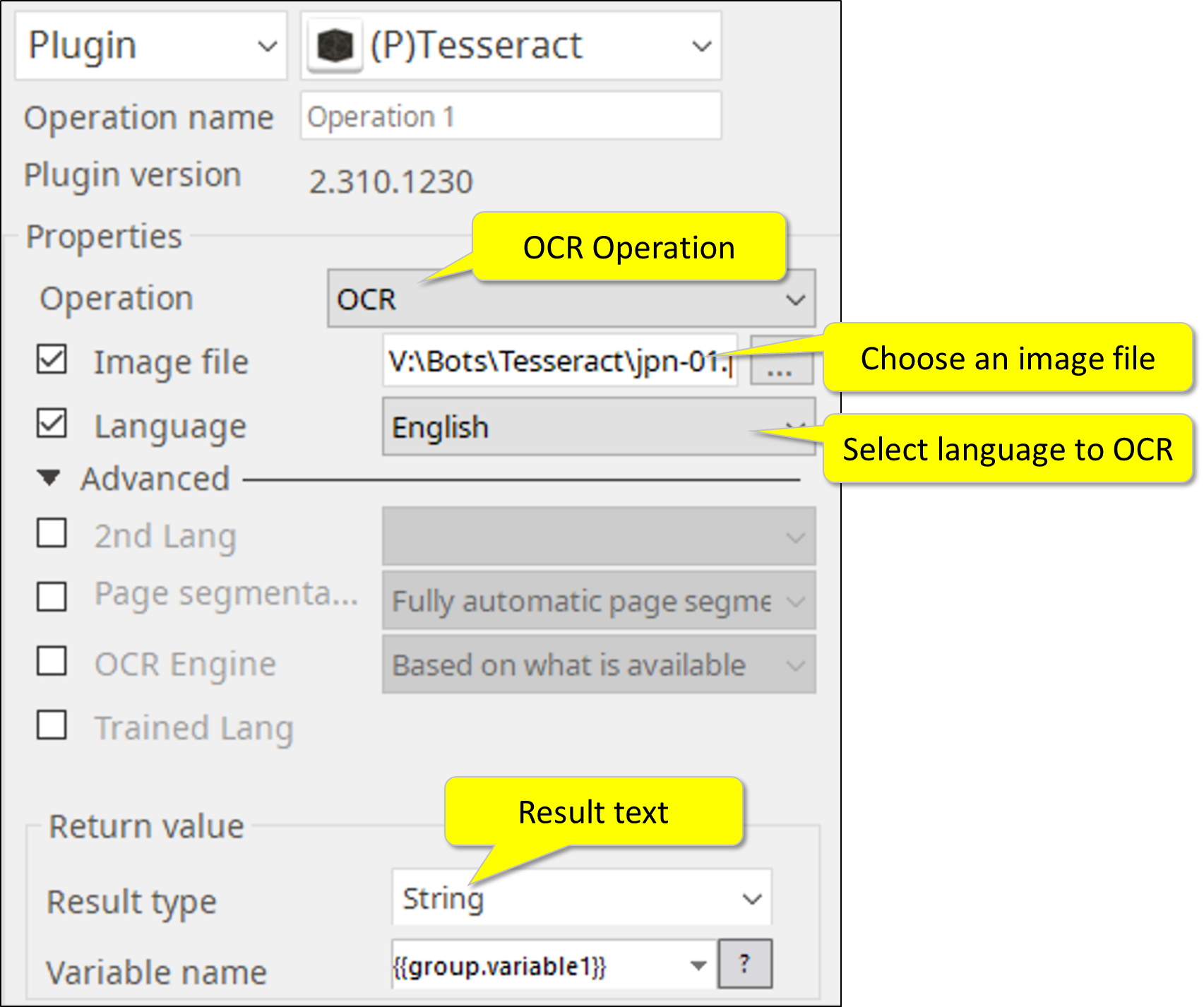
3. OCR
Return value contains the OCR results in String.
Page segmentation options can be chosen from 13 options.
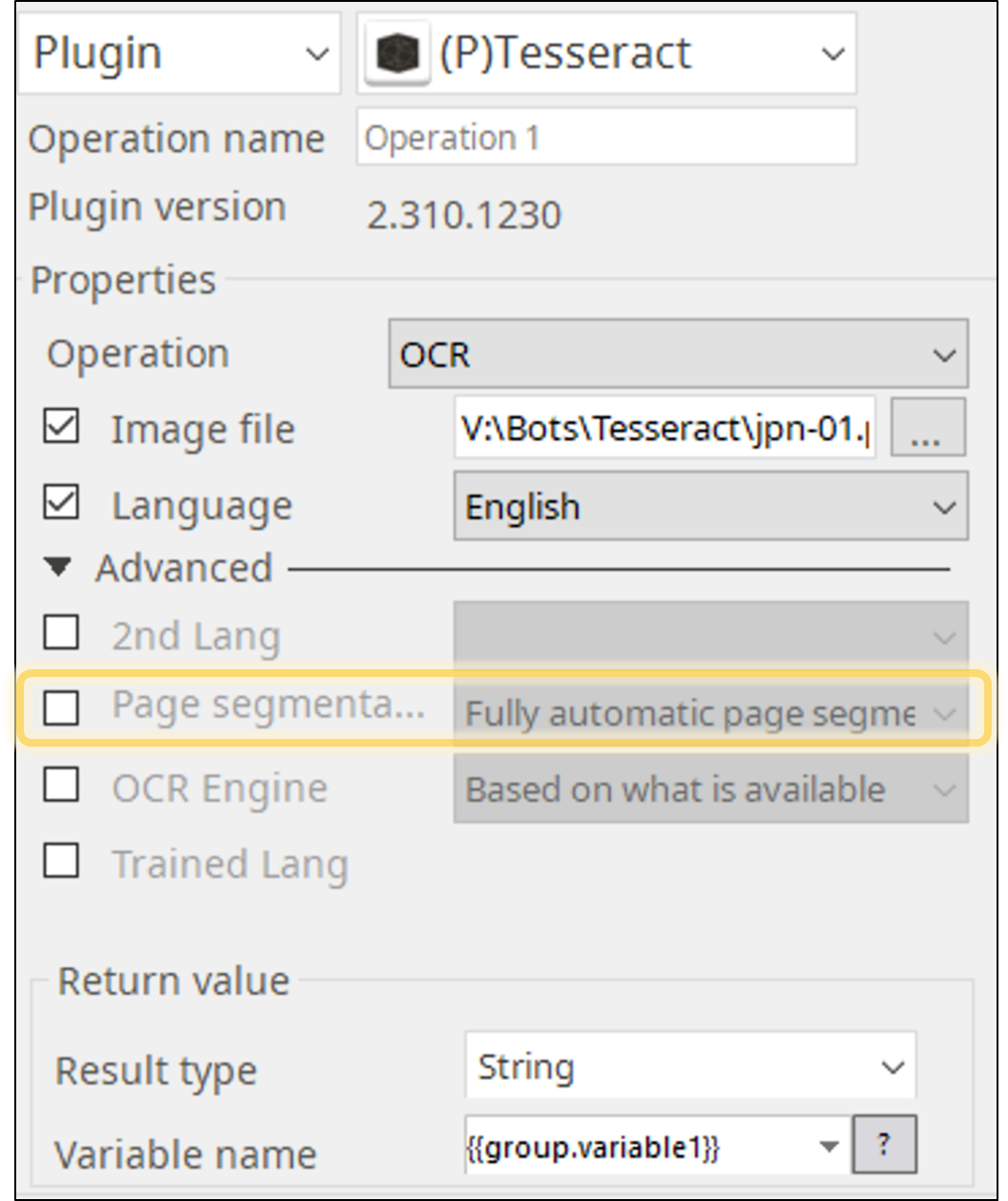
- 0 Orientation and script detection (OSD) only.
- 1 Automatic page segmentation with OSD.
- 2 Automatic page segmentation, but no OSD, or OCR.
- 3 Fully automatic page segmentation, but no OSD. (Default)
- 4 Assume a single column of text of variable sizes.
- 5 Assume a single uniform block of vertically aligned text.
- 6 Assume a single uniform block of text.
- 7 Treat the image as a single text line.
- 8 Treat the image as a single word.
- 9 Treat the image as a single word in a circle.
- 10 Treat the image as a single character.
- 11 Sparse text. Find as much text as possible in no particular order.
- 12 Sparse text with OSD.
- 13 Raw line. Treat the image as a single text line, bypassing hacks that are Tesseract-specific.
OCR Engine selection options
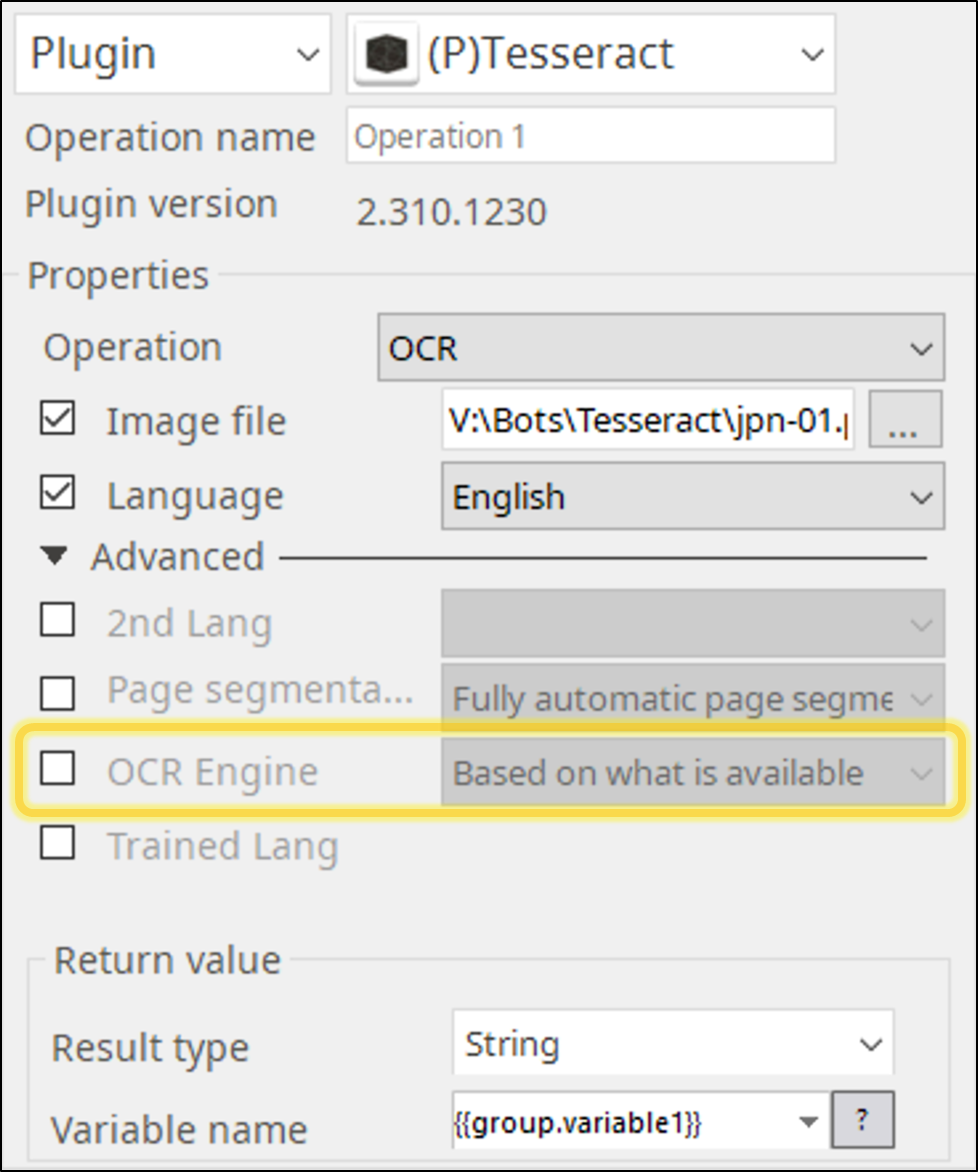
- 0 Original Tesseract only.
- 1 Neural nets LSTM only.
- 2 Tesseract + LSTM.
- 3 Default, based on what is available.
- ABBYY Download
- ABBYY Status
- ABBYY Upload
- AD LDAP
- Adv Send Email
- API Requests
- ARGOS API
- Arithmetic Op
- ASCII Converter
- Attach Image
- AWS S3
- AWS Textra Rekog
- Base64
- Basic Numerical Operations
- Basic String Manipulation
- Bot Collabo
- Box
- Box II
- Chatwork GetMessage
- Chatwork Notification
- Citizen Log
- Clipboard
- Codat API
- Convert CharSet
- Convert Image
- Convert Image II
- Create Newfile
- CSV2XLSX
- Dashboard Api
- DashBord Api
- Data Plot I
- Date OP
- DeepL Free
- Detect CharSet
- Dialog Calendar
- Dialog Error
- Dialog File Selection
- Dialog Forms
- Dialog Info
- Dialog Password
- Dialog Question
- Dialog Text Entry
- Dialog Text Info
- Dialog Warning
- DirectCloud API
- Doc2TXT
- DocDigitizer Get Doc
- DocDigitizer Tracking
- DocDigitizer Upload
- Drag and Drop
- Dropbox
- Dynamic Python
- Email IMAP ReadMon
- Email Read Mon
- Env Check
- Env Var
- Excel2Image
- Excel Advanced
- Excel Advance IV
- Excel AdvII
- Excel AdvIII
- Excel Copy Paste
- Excel Formula
- Excel Large Files
- Excel Macro
- Excel Newfile
- Excel Simple Read
- Excel Simple Write
- Excel Style
- Excel Update
- Fairy Devices mimi AI
- File Conv
- File Downloader
- File Folder Exists
- File Folder Op
- File Status
- Fixed Form Processing
- Floating Form Processing
- Folder Monitor
- Folder Status
- Folder Structure
- FTP Server
- Git HTML Extract
- Google Calendar
- Google Cloud Vision API
- Google Drive
- Google Search API
- Google Sheets
- Google Token
- Google Translate
- Google TTS
- GraphQL API
- Html Extract
- HTML Table
- IBM Speech to Text
- IBM Visual Recognition
- Java UI Automation
- JP Holiday
- JSON Select
- JSON to from CSV
- Lazarus Forms
- Lazarus FTP
- Lazarus Grid
- Lazarus Invoices
- Lazarus RikAI
- Lazarus RikAI2
- Lazarus RikAI2 Async
- Lazarus Riky
- Lazarus VKG
- LINE ID Card OCR
- LINE Notify
- LINE Receipt OCR
- Mangdoc AI Docs
- Microsoft Teams
- MongoDB
- MQTT Publisher
- MS Azure Text Analytics
- MS-SQL
- MS Word Extract
- NAVER OCR
- Newuser-SFDC
- OCI
- OCR PreProcess
- OpenAI API
- Oracle SQL
- Outlook
- Outlook Email
- PANDAS I
- pandas II
- pandas III
- PANDAS profiling
- Parsehub
- Password Generate
- Path Manipulation
- PDF2Doc
- PDF2Table
- PDF2TXT
- PDF Miner
- PDF SplitMerge
- PDF Viewer(Start/Stop)
- PostgreSQL
- Power Query
- PowerShell
- PPTX Template
- Print 2 Image
- Python Selenium
- QR Generate
- QR Read
- RakurakuHanbai API
- Regression
- Rename File
- REST API
- Rossum
- Running GAS
- Scrapy Basic
- Screen Capture
- Screen Recording START
- Screen Recording STOP
- Screen Snipping
- Seaborn Plot
- SharePoint
- Simple Counter
- Simple SFDC
- Slack
- Sort CSV
- Speed Test
- SQL
- SQLite
- SSH Command
- SSH Copy
- String Manipulation
- String Similarity
- Svc Check
- Sys Info
- Telegram
- Tesseract
- Text2PDF
- Text2Word
- Text Read
- Text Write
- Time Diff
- Time Stamp
- Web Extract
- Windows Op
- Windows Screen Lock
- Win UI Control
- Win UI Text
- Word2PDF
- Word2TXT
- Word Editor
- Work Calendar
- XML Extract
- XML Manipulation
- Xtracta Get Doc
- Xtracta Tracking
- Xtracta Upload
- YouTube Operation
- ZipUnzip