pandas III
- ARGOSLABS
| pandas III |
|---|---|
Author: Jerry Chae Now capable of processing multiple input data files. (dataframes) This is the third plugin in our pandas series. This is similar to panda-II where users can execute their Python statement sequentially like Jupyter Notebook but automatically (without Jupyter Notebook) with pandas-III. The major difference is that pandas-III enables you to take multiple data files as input.
Primary Features This plugin runs python statement(s) on pandas on multiple input data files (dataframes).
Prerequisite This plugin requires Python and Regular Expression skills. |

![]() Initial download maybe slow
Initial download maybe slow
Please note that the pandas solution is a large software using numerous Python machine learning sub-modules. The bot will take more than just a few minutes to download them to be ready. But this is just for the “first run”. As to the second run on, the local VENV will be used to avoid downloading unless new pandas II version has been selected to replace what was in the bot originally.
Update 2021.03.11
You only need the BODY part of your pandas statements to drive the pandas-II and -III plugins.
The pandas-II and -III plugins have integrated the importing, reading, and the saving parts, you only need the body part of your statements. For example, when your pandas statements look like below you only need one line in the pandas-II and -III plugins.
For pandas-II

For pandas-III

Update 2021.02.22
Sample Statements and Use of “df” and “dfs” variables
1. You must use “df” and “dfs” as variables for data-frames
a. As variable for the dataframes with the Python statements in pandas II and III plugins, it is required to use "df" and "dfs" to represent dataframes (all in small cases).
b. As for pandas III, the multiple dataframes ("dfs“) will take [n] as index (it is zero based as the first set of dataframe becomes dfs[0]) as shown in examples below.
2. For pandas II Statements
a. The “In file” will be the data frame stored at "df" Python variable
b. All pandas functionality is working with "df" data frame including Reshaping at statements File
c. Processed results of statement’s execution will continue to be stored in the same "df“ variable and eventually be the “Out file”
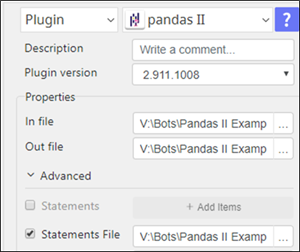
3. pandas II Statements Example
- df['BMI'] = df['Kilograms'] / ((df ['Centimeters'] / 100.0)*(df ['Centimeters'] / 100.0))
- df = df.sort_values('BMI', ascending=False)
- df = df.sort_values('BMI', ascending=False).groupby('Gender').head(5)
4. pandas III Statements
a. “In files” will be a data frame stored at "dfs[0]", "dfs[1]",... Python variable (zero base index)
b. All pandas functionality is working with "dfs[n]" data frames including merge
c. Processed results of statement’s execution will continue to be stored in the same "df“ variable and eventually be the “Out file”
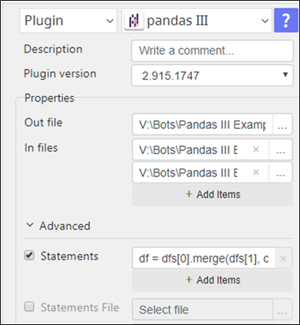
5. pandas III Statements Example
- df = dfs[0].merge(dfs[1], on='sku', how='left')
Above Python represents the process illustrated below (just like vlookup feature in Excel)
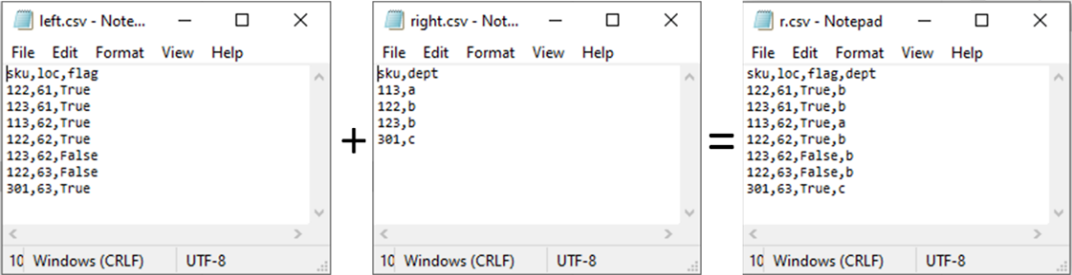
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
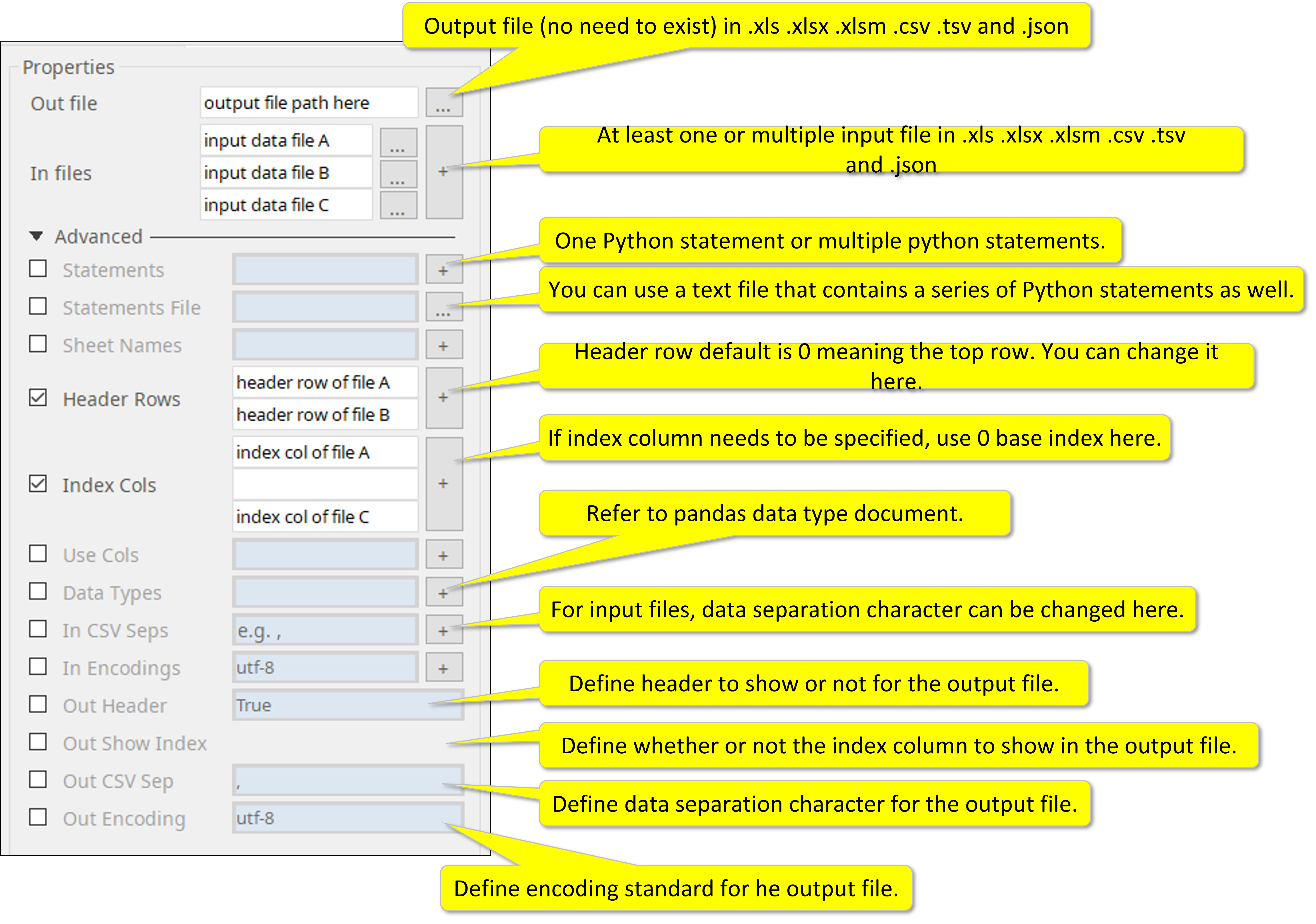
Input, Output, Features, and Parameters.
Required Input
1. Output File: One data file.
Supported input formats are .xlsm, .xls, xlsm, .csv, .tsv, and .json
2. Input Files: as many data files (dataframe) as you would like to process.
Supported input formats are .xlsm, .xls, xlsm, .csv, .tsv, and .json
Optional Input
3. Enter a Python statement, or multiple statements. Also a text file that contains a list of statements can be used as input.
4. When input file multiple sheets, you can select which sheet to be processed.
5. You can designate which row you can use as header (variable) for your processing.
6. You can specify a column to be used as the index of the dataframe.
7. You can specify which column(s) to be or not to be processed.
8. You can determine specific pandas datatypes for your column.
9. You can determine what character to use to separate your data (default is comma).
10. You can specify encoding technology of the input file (default is UTF-8).
11. You can select to either show or hide the index column in your output file.
How to set parameters
When handling multiple input data files, you must respect the input file sequence to set parameters for each one of the input files.
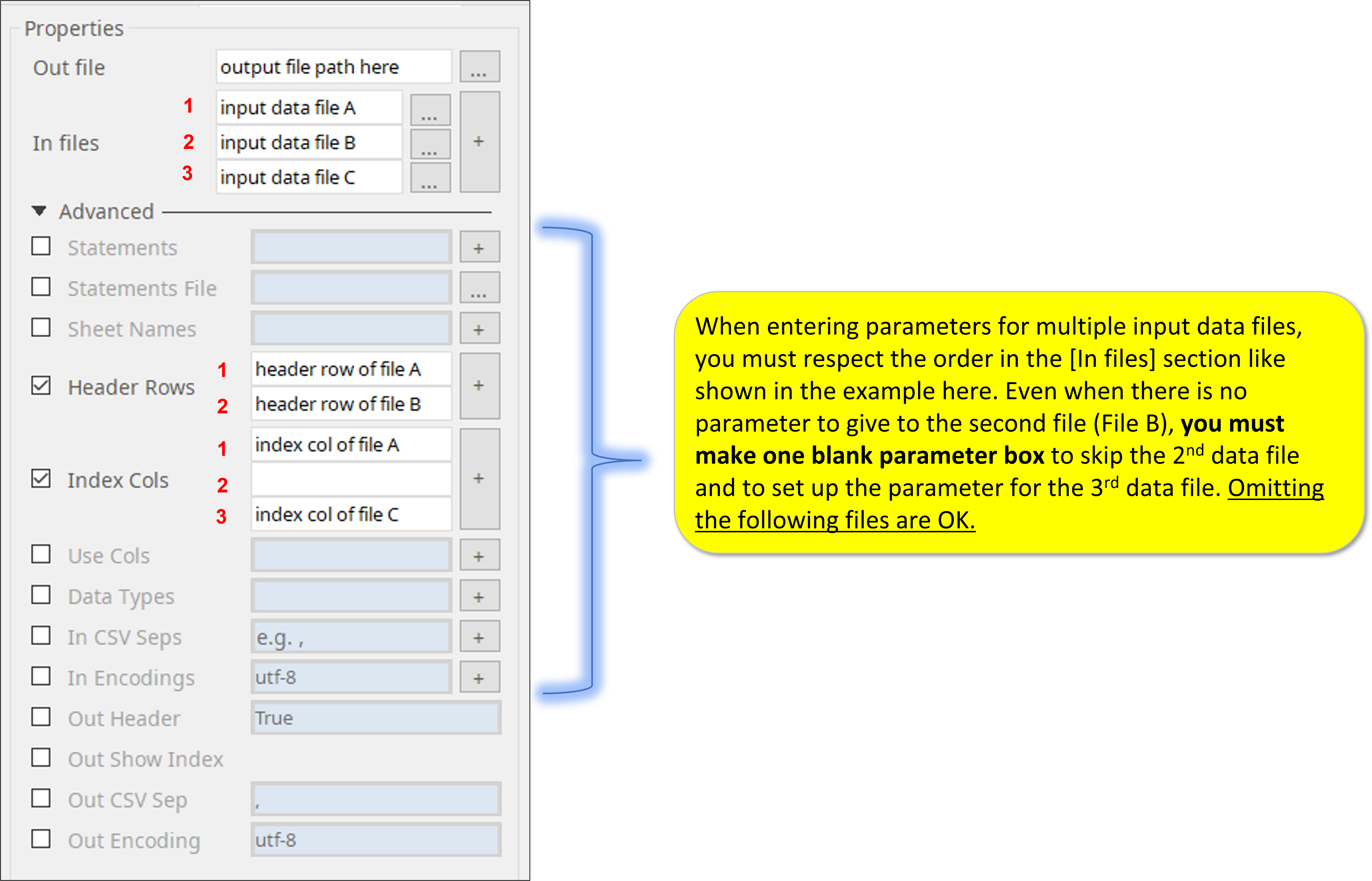
pandas-III plugin parameters are 100% compatible to pandas read_excel specifications
Please refer the parameters on the right in the pandas document above.
- Sheet Name →sheet_name
- Header Row →header
- Index Col →index_cols
- Use Col →usecols
- Data Type →dtypes
- ABBYY Download
- ABBYY Status
- ABBYY Upload
- AD LDAP
- Adv Send Email
- API Requests
- ARGOS API
- Arithmetic Op
- ASCII Converter
- Attach Image
- AWS S3
- AWS Textra Rekog
- Base64
- Basic Numerical Operations
- Basic String Manipulation
- Bot Collabo
- Box
- Box II
- Chatwork GetMessage
- Chatwork Notification
- Citizen Log
- Clipboard
- Codat API
- Convert CharSet
- Convert Image
- Convert Image II
- Create Newfile
- CSV2XLSX
- Dashboard Api
- DashBord Api
- Data Plot I
- Date OP
- DeepL Free
- Detect CharSet
- Dialog Calendar
- Dialog Error
- Dialog File Selection
- Dialog Forms
- Dialog Info
- Dialog Password
- Dialog Question
- Dialog Text Entry
- Dialog Text Info
- Dialog Warning
- DirectCloud API
- Doc2TXT
- DocDigitizer Get Doc
- DocDigitizer Tracking
- DocDigitizer Upload
- Drag and Drop
- Dropbox
- Dynamic Python
- Email IMAP ReadMon
- Email Read Mon
- Env Check
- Env Var
- Excel2Image
- Excel Advanced
- Excel Advance IV
- Excel AdvII
- Excel AdvIII
- Excel Copy Paste
- Excel Formula
- Excel Large Files
- Excel Macro
- Excel Newfile
- Excel Simple Read
- Excel Simple Write
- Excel Style
- Excel Update
- Fairy Devices mimi AI
- File Conv
- File Downloader
- File Folder Exists
- File Folder Op
- File Status
- Fixed Form Processing
- Floating Form Processing
- Folder Monitor
- Folder Status
- Folder Structure
- FTP Server
- Git HTML Extract
- Google Calendar
- Google Cloud Vision API
- Google Drive
- Google Search API
- Google Sheets
- Google Token
- Google Translate
- Google TTS
- GraphQL API
- Html Extract
- HTML Table
- IBM Speech to Text
- IBM Visual Recognition
- Java UI Automation
- JP Holiday
- JSON Select
- JSON to from CSV
- Lazarus Forms
- Lazarus FTP
- Lazarus Grid
- Lazarus Invoices
- Lazarus RikAI
- Lazarus RikAI2
- Lazarus RikAI2 Async
- Lazarus Riky
- Lazarus VKG
- LINE ID Card OCR
- LINE Notify
- LINE Receipt OCR
- Mangdoc AI Docs
- Microsoft Teams
- MongoDB
- MQTT Publisher
- MS Azure Text Analytics
- MS-SQL
- MS Word Extract
- NAVER OCR
- Newuser-SFDC
- OCI
- OCR PreProcess
- OpenAI API
- Oracle SQL
- Outlook
- Outlook Email
- PANDAS I
- pandas II
- pandas III
- PANDAS profiling
- Parsehub
- Password Generate
- Path Manipulation
- PDF2Doc
- PDF2Table
- PDF2TXT
- PDF Miner
- PDF SplitMerge
- PDF Viewer(Start/Stop)
- PostgreSQL
- Power Query
- PowerShell
- PPTX Template
- Print 2 Image
- Python Selenium
- QR Generate
- QR Read
- RakurakuHanbai API
- Regression
- Rename File
- REST API
- Rossum
- Running GAS
- Scrapy Basic
- Screen Capture
- Screen Recording START
- Screen Recording STOP
- Screen Snipping
- Seaborn Plot
- SharePoint
- Simple Counter
- Simple SFDC
- Slack
- Sort CSV
- Speed Test
- SQL
- SQLite
- SSH Command
- SSH Copy
- String Manipulation
- String Similarity
- Svc Check
- Sys Info
- Telegram
- Tesseract
- Text2PDF
- Text2Word
- Text Read
- Text Write
- Time Diff
- Time Stamp
- Web Extract
- Windows Op
- Windows Screen Lock
- Win UI Control
- Win UI Text
- Word2PDF
- Word2TXT
- Word Editor
- Work Calendar
- XML Extract
- XML Manipulation
- Xtracta Get Doc
- Xtracta Tracking
- Xtracta Upload
- YouTube Operation
- ZipUnzip