OCR
- ARGOSLABS
Step 0. Where to find your saved OCR Text.
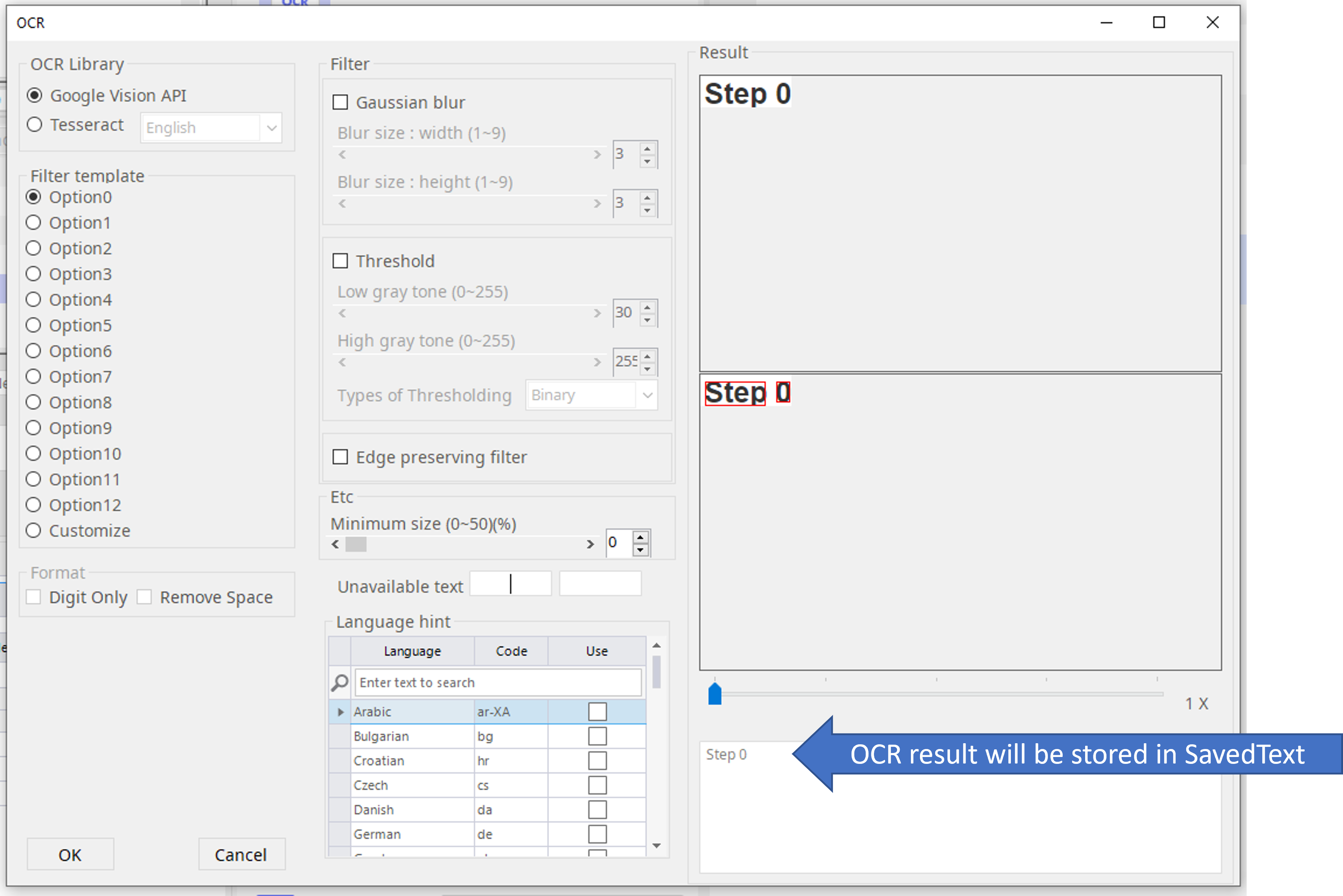
The text result of OCR is saved in the Saved Text option in the Type Input operation. (Variable type is string.)

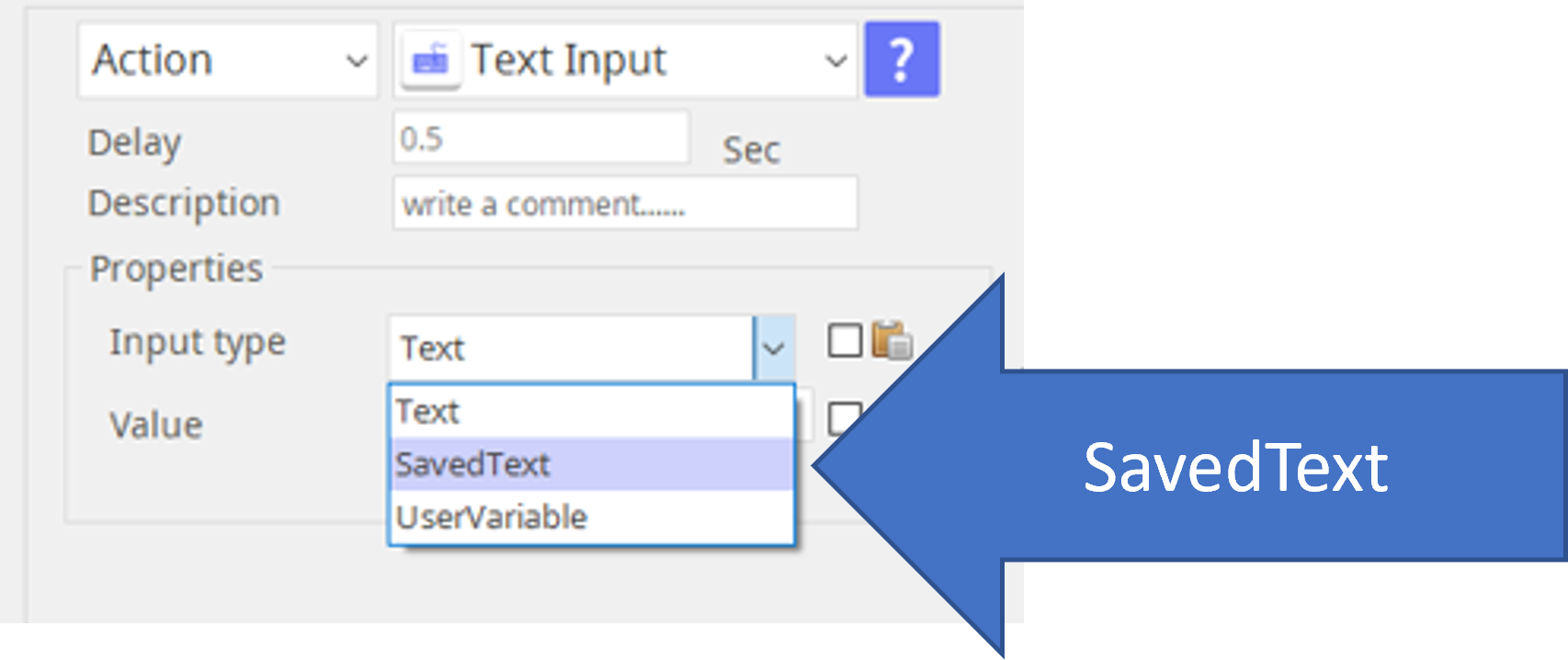
The result text string is saved here!
Step 1. Take screenshot.
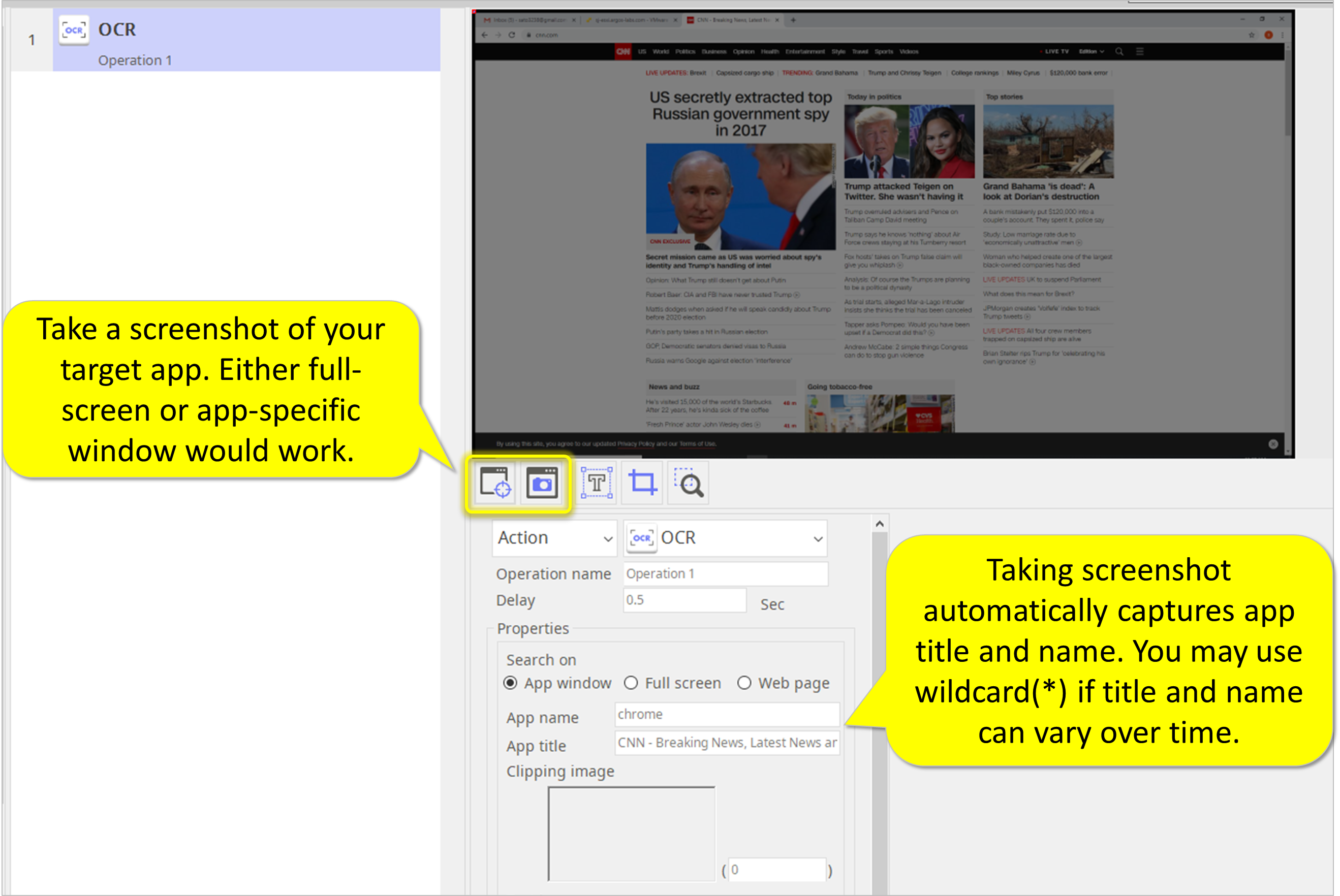
- Take a screenshot of your target app. Either full-screen or app-specific window would work.
- Taking screenshot automatically captures app title and name. You may use wildcard(*) if title and name can vary over time.
Step 2. Select a reference (anchoring) image. Note this is NOT the image to run OCR on.
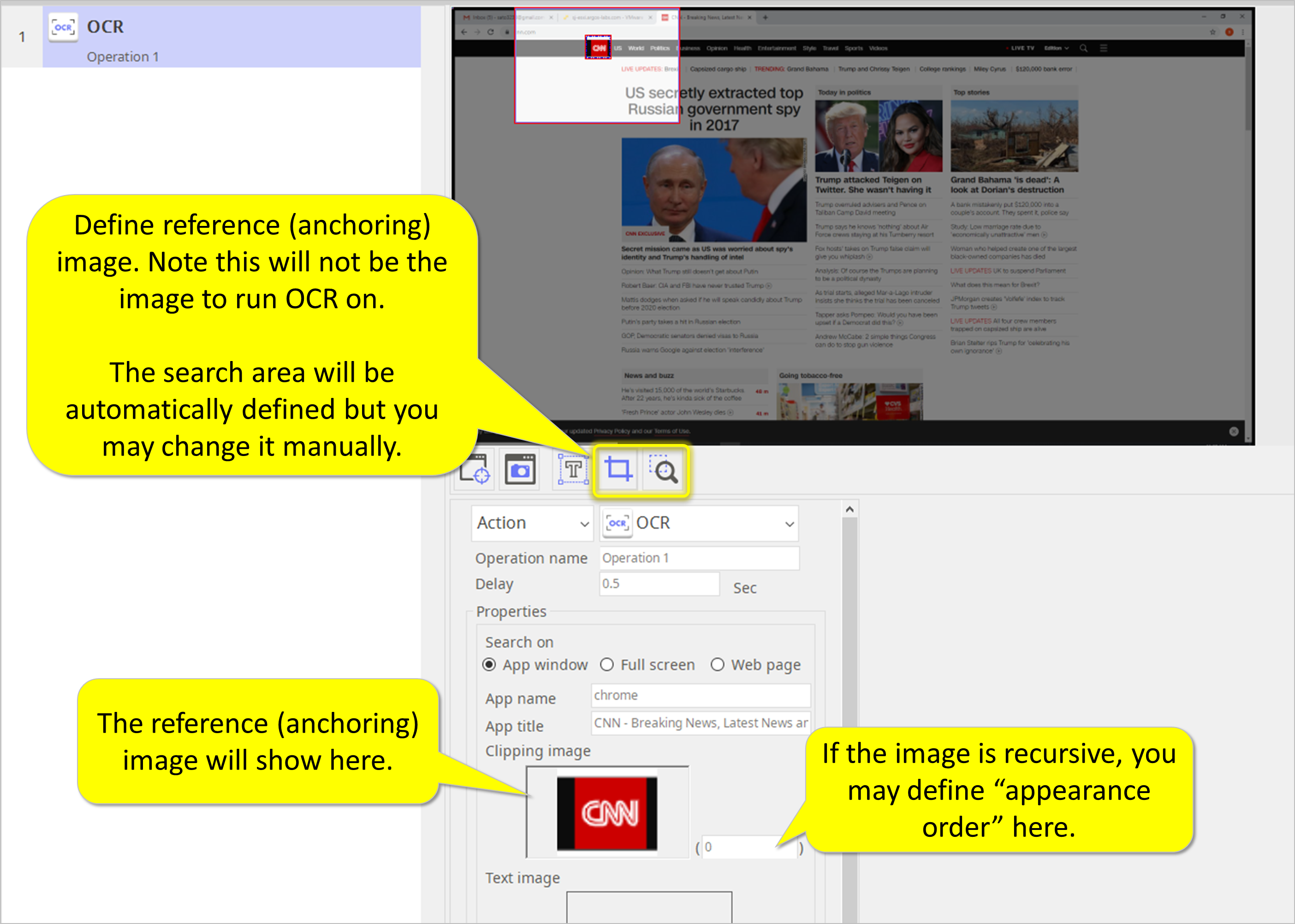
- Define reference (anchoring) image. Note this will not be the image to run OCR on. The search area will be automatically defined but you may change it manually.
- The reference (anchoring) image will show here.
- If the image is recursive, you may define “appearance order” here.
Step 3. Select target image to run OCR on.
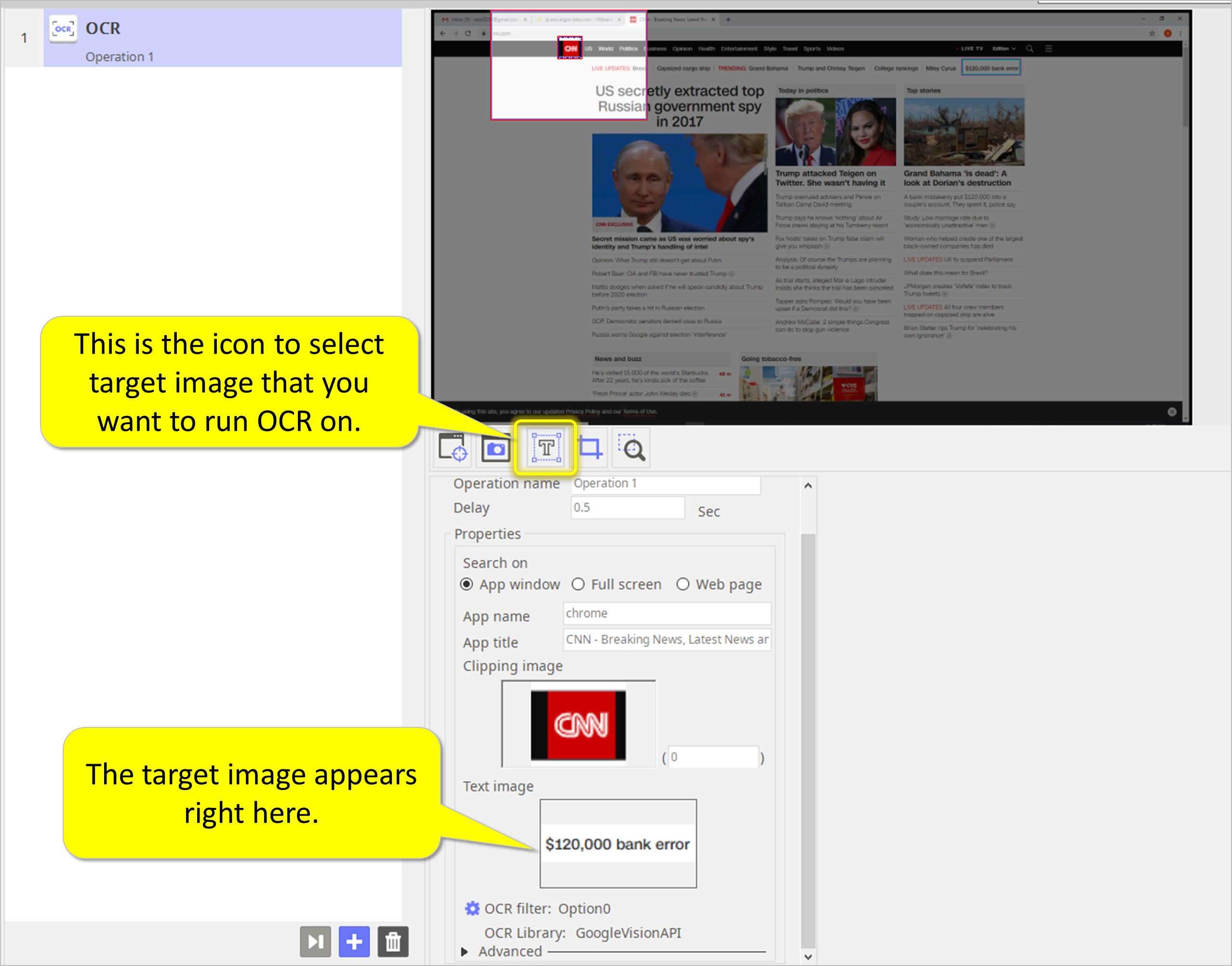
- This is the icon to select target image that you want to run OCR on.
- The target image appears right here.
Step 4. Click on the cogwheel and choose the OCR technology.
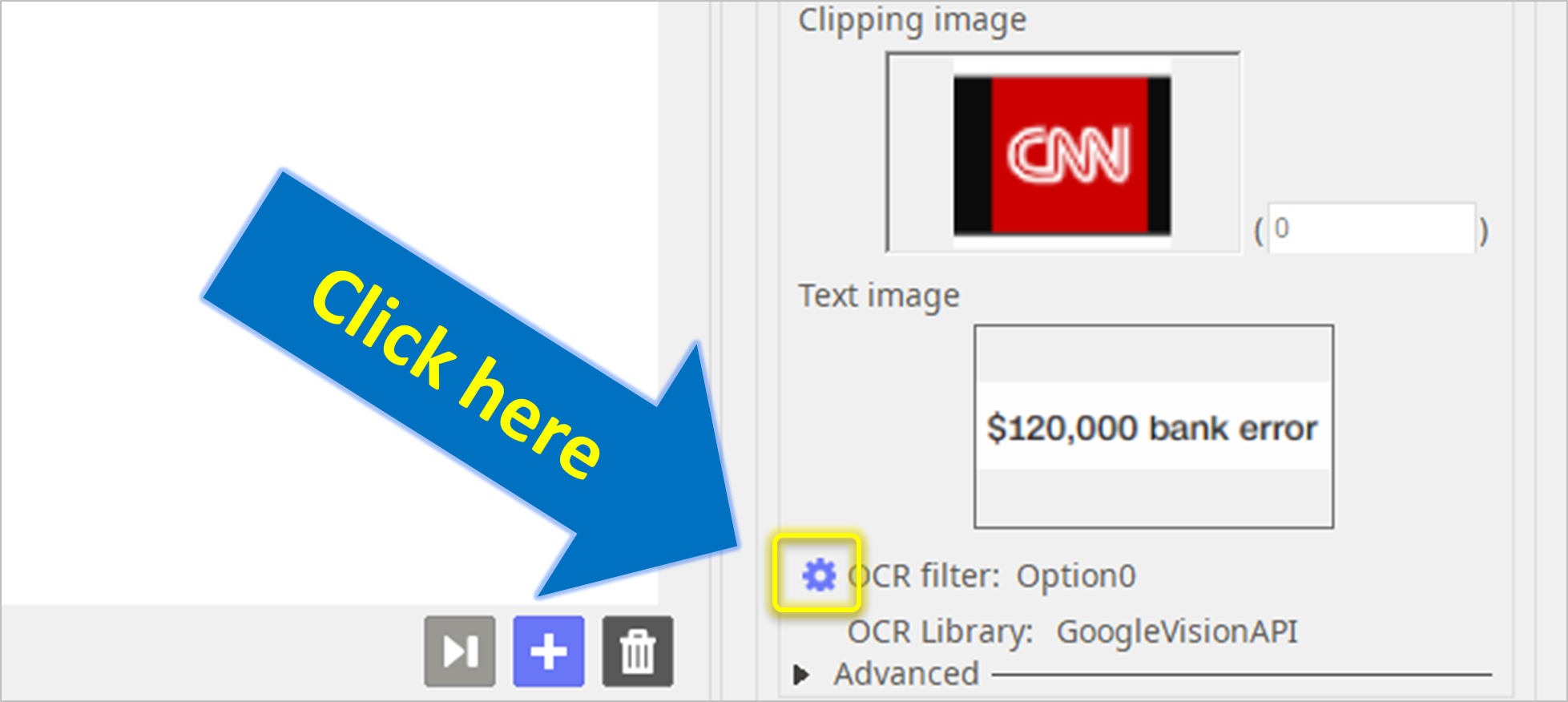
- Click here

If you check the 'Google Vision API(USer credential). Follow the link

Left Text Bubble
Google Vision Requires Your Own Credentials
- Various parameters are available from different libraries
Right Text Bubble
- $$$ Some OCR libraries requires user account and commercial contract
- Your OCR results shows here.
Please note that some OCR libraries require separate user account and commercial arrangement (contract) for large usages.
**Troubleshooting Tips**

<image of the error message>
Please note that Tesseract trained file can be "damaged" for one reason or another. In this case, OCR cannot be executed and STU/PAM will issue an error message that reads “Tesseract TrainedData is Not Existed, please download trained data file.”.
To fix this, please re-save the trained file which is damaged at the following path.
- %programdata%\tesseract trained data
Tesseract trained data can be downloaded from the following link.
https://github.com/tesseract-ocr/tessdata